概述
数据库(database) 保存有组织的数据的容器(通常是一个或一组文件)
数据库管理系统(DBMS,Database Management System) 一种软件,创建和操控数据库
表(table) 某种特定类型数据的结构化清单。表名相对于同一个数据库唯一,但不同的数据库中可以使用相同的表名。
模式(schema) 关于数据库和表的布局及特性信息。
列(column) 表中的一个字段。所有表都是由一个列或多个列组成。每个列都有相应的数据类型
数据类型(datatype) 所容许的数据的类型。每个列对应的数据类型来限制,该列存储的数据。比如有 int、varchar、datatime、double等(重点)
行(row) 表中的一个记录
主键(primary key) 一列中或一组列,其值唯一区分表中的每一个行。
定义主键方便只涉及相关行的操作。
任意两行主键值不相同。每行的主键不能为空(NULL)。
建议不更新主键列的值,不主键列的值,不把经常需要修改的列设置主键列,例如什么什么的名称
SQL(Structured Query Language) 专门用于与数据库通信的语言
数据库分类:
- 关系型数据库 (SQL)
MySQL、Oracle、SQL Server、DB2、SQLite
- 非关系型数据库 (NoSQL, Not Only SQL)
Redis、MongoDB
MySQL版本
- 4 InnoDB引擎,事务处理,并,改进全文本搜索
- 4.1 对函数库、子查询、集成帮助等的重要增加
- 5 存储过程、触发器、游标、视图等等
基本命令行
连接
mysql -u 用户名 -p口令 -h 主机名 -P 对口号
mysql -u root -proot -h 127.0.0.1 -P 3306
选择数据库
USE `数据库名`;
USE `crashcourse`;
了解数据库和表
SHOW DATABASES; -- 返回可用数据库的一个列表
SHOW TABLES; -- 返回当前选择的数据库内可用表的列表
SHOW COLUMNS FROM 表名; -- 返回字段描述信息
DESCRIBE 表名; -- 上一行的快捷方式
SHOW STATUS; -- 用于显示广泛的服务器状态信息
SHOW CREATE DATABASE 数据库名; -- 显示创建特定数据库的MySQL语句
SHOW CREATE TABLE 表名; -- 显示创建特定表的MySQL语句
SHOW GRANTS FOR 用户名; -- 用来显示授予用户的安全权限
SHOW ERRORS; -- 用来显示服务器错误
SHOW WARNINGS; -- 用来显示服务器警告信息
退出连接
exit;
SQL命令类型
- DDL(Data Definition Language) 数据库定义语言
create|drop|alter|truncate|comment|rename
- DML(Data Manipulation Language)数据库操作语言
insert|update|delete
- DQL(Data query Language) 数据库查询语言
select
- DCL(Data Control Language) 数据库控制语言
grant|revoke
- TCL(Transaction Control Language) 事务控制语言
commit|rollback|savepoint|set transaction
操作数据库
创建数据库
CREATE DATABASE [IF NOT EXISTS] `数据库名`;
CREATE DATABASE IF NOT EXISTS `crashcourse`;
删除数据库
DROP DATABASE [IF EXISTS] `数据库名`;
DROP DATABASE IF NOT EXISTS `crashcourse`;
注意 :操作或创建数据库的表时,要先选择数据库。
数据类型
串数据类型
- char 字符数固定大小的 长度0~255 存储方式:数据
- varchar 字符数可变字符串 长度0~65535 存储方式:长度前缀+数据
- tinytext 微型变长文本 长度0~2^8-1
- text 变长文本串 长度0~2^16-1
数值类型
- tinyint 十分小的整数 大小1B
- smallint 较小的整数 大小2B
- mediumint 中等大小整数 大小3B
- int 标准整数 大小4B
- bigint 较大整数 大小8B
- float 单精度浮点 大小4B
- double 双精度浮点 大小8B
- decimal 精度可变的浮点数 金融计算使用decimal(p, d) p:有效数字的字数 d:小数点后位数。
时间日期类型
- date YYYY-mm-dd
- time HH:MM:SS
- datetime YYYY-mm-dd HH:MM:SS
- timestamp 时间戳
- Year 年
NULL
没有值,未知。
不建议使用NULL进行==运算
数据库字段属性
- UNSIGNED 无符号整数 不可填充负数
- ZEROFILL 0填充 不足位数用0填充
- AUTO_INCREMENT 自增 在上条记录基础上加1 必须整数类型 可设置起始值和步长值
- NOT NULL|NULL 允许非空或空
- DEFAULT 默认值
数据库表固定的几个样板字段
- id 主键
- version 乐观锁
- is_delete 伪删除
- gmt_create 创建时间
- gmt_update 更新时间
建立表
例如建立学生表:
| 字段 | 类型 |
|---|---|
| 学号id | int(4) |
| 密码pwd | varchar(20) |
| 姓名name | varchar(3) |
| 性别gender | varchar(2) |
| 出生日期birth | datetime |
| 家庭住址address | varchar(100) |
| 电子邮箱email | varchar(50) |
CREATE TABLE IF NOT EXISTS `student` (
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(3) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`gender` VARCHAR(2) NOT NULL DEFAULT '男' COMMENT '性别',
`birth` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '电子邮箱',
PRIMARY KEY(`id`)
) ENGINE=INNODB DEFAULT CHARSET=UTF8;
输出:
OK, Time: 0.022000s
格式:
CREATE TABLE [IF NOT EXISTS] 表名 (
`字段名` 数据类型 [属性] [索引] [注释],
`字段名` 数据类型 [属性] [索引] [注释],
...
`字段名` 数据类型 [属性] [索引] [注释]
)[存储引擎][字符集设置][注释]
INNODB与MYISAM
区别:
| MYISAM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持,但支持表锁 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文搜索 | 支持 | 不支持 |
| 表空间大小 | 较小 | 较大,约为MYISAM的两倍 |
优点:
- MYISAM 节约空间,速度快
- INNODB 安全性高,事务处理,多表多用户操作
数据库文件存放位置
在Linux操作系统,mysql数据目录在/var/lib/mysql下(docker的mysql默认的位置)。
Window可能在mysql家目录的data目录下(据实际情况而定)。
Mac在/usr/local/var/mysql中(brew安装的话)。
一个文件夹对应数据库,如下:
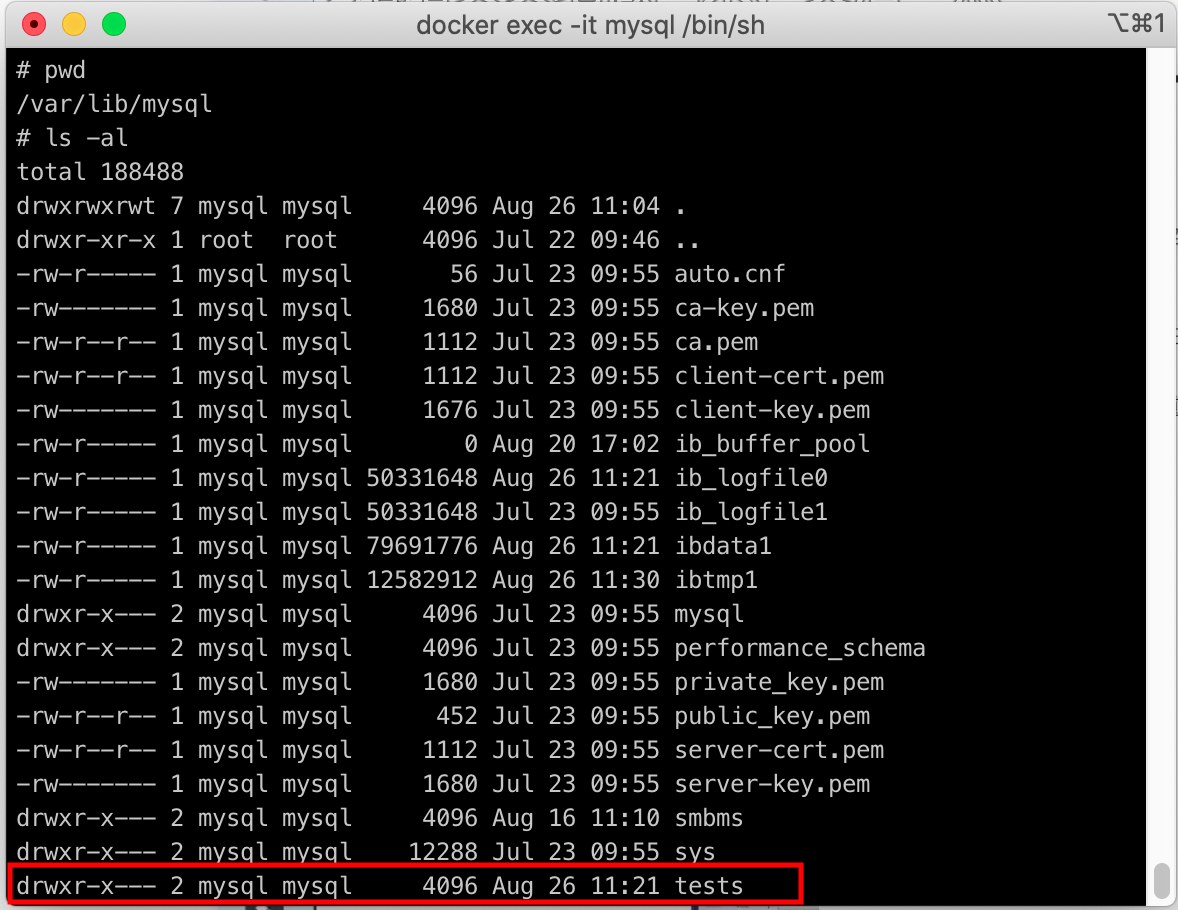
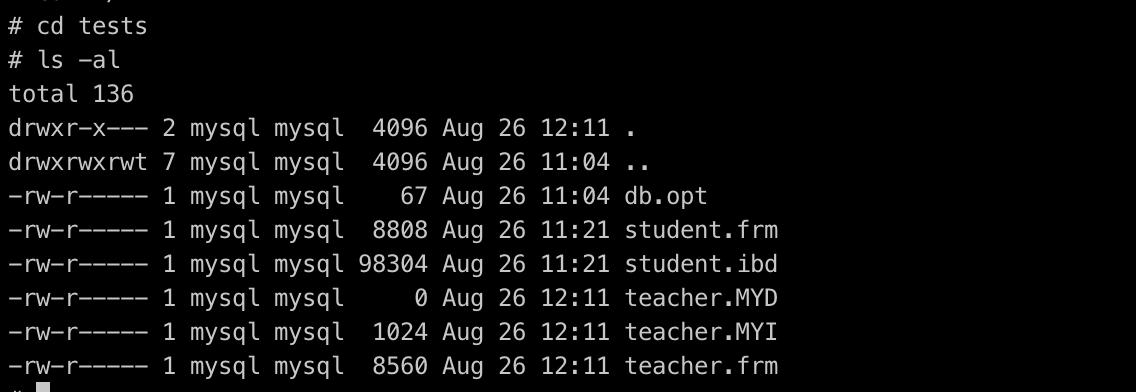
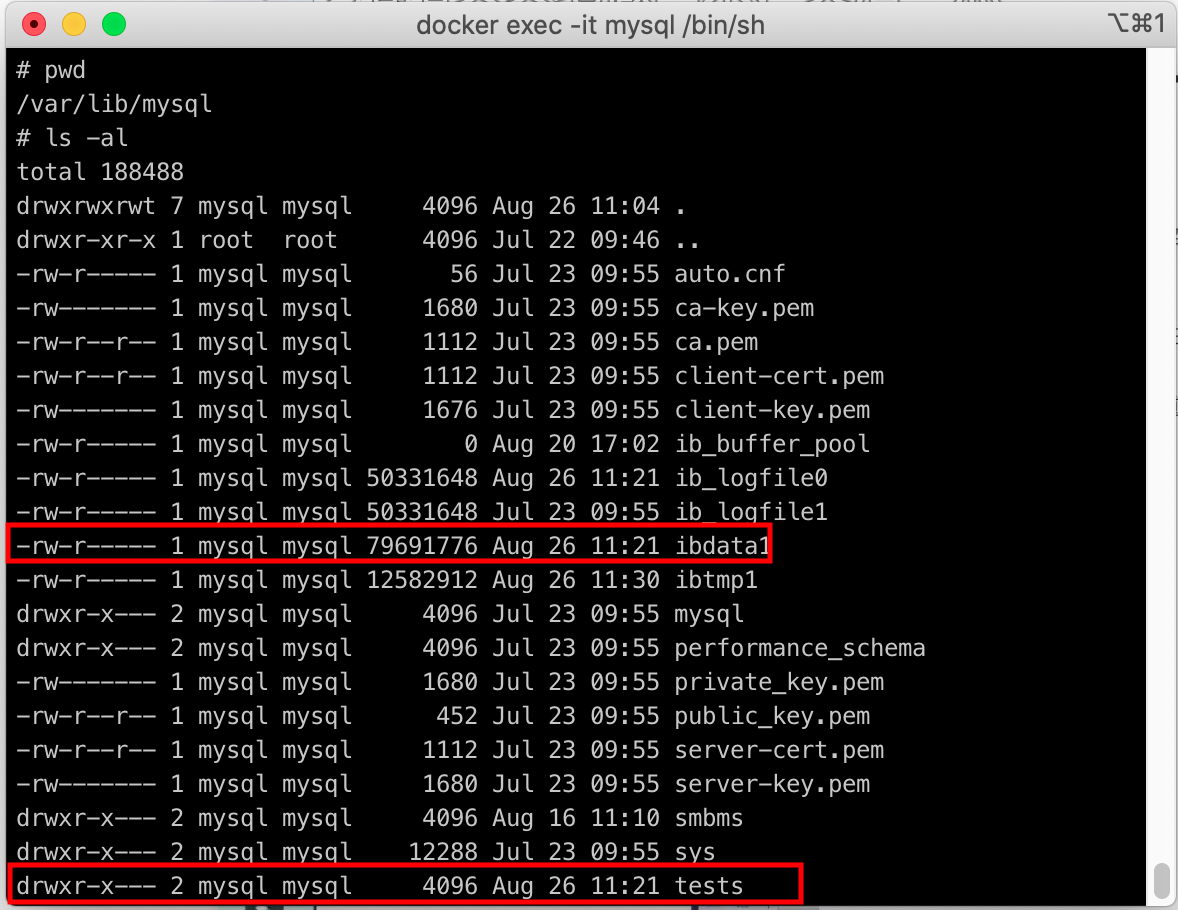
MySQL存储引擎在文件上的区别:
- INNODB在数据库tests文件夹中只有*.frm文件,上级目录的ibdata1数据文件
- MYISAM在数据库tests文件夹中有:
- *.frm 表结构定义文件
- *.MYD 数据文件
- *.MYI 索引文件
更新表
完全限定表名:`数据库`.`表`
修改表名
ALTER TABLE `旧表名` RENAME AS `新表名`;
ALTER TABLE `student` RENAME AS `stu`;
RENAME TABLE `旧表名` TO `新表名`;
RENAME TABLE `student` TO `stu`;
新增字段
ALTER TABLE `表名` ADD `字段名` 数据类型 属性;
ALTER TABLE `student` ADD `gradeId` INT(11) NOT NULL COMMENT '班级';
修改字段(重命名,约束)
change 字段名、数据类型、属性都能修改
modify 除了字段名不能更改和change一样
ALTER TABLE `表名` CHANGE `旧字段名` `新字段名` 数据类型;
ALTER TABLE `student` CHANGE `name` `stuName` VARCHAR(10) NOT NULL DEFAULT '匿名' COMMENT '学生姓名';
ALTER TABLE `表名` MODIFY `字段名` 新数据类型 属性;
ALTER TABLE `student` MODIFY `stuName` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '学生姓名';
删除字段
ALTER TABLE `表名` DROP `字段名`;
删除表
DROP TABLE [IF EXISTS] `表名`;
数据管理
外键
CREATE TABLE IF NOT EXISTS `grade` (
`gradeId` INT(11) NOT NULL AUTO_INCREMENT,
`gradeName` VARCHAR(10) NOT NULL DEFAULT '未知',
PRIMARY KEY(`gradeId`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
ALTER TABLE `表名` ADD CONSTRAINT `约束名` FOREIGN KEY(`外键名`) REFERENCES `引用表名`(`关联外键的字段名`);
ALTER TABLE `student` ADD CONSTRAINT `fk_student_grade` FOREIGN KEY(`gradeId`) REFERENCES `grade`(`gradeId`);
已经不建议使用物理外键,以后可以使用程序实现逻辑外键,代码更易维护。
新增
INSERT INTO `表名`[(字段1,字段2,字段N)]
VALUES (值1,值2,值N) [,(值1,值2,值N)];
INSERT INTO `grade`(`gradeName`)
VALUES('一年级'),('二年级'),('三年级');
INSERT INTO `student`
VALUES(NULL,'张三','123456','男','1999-08-08','广东广州','zhangsan@163.com',1),
(NULL,'李四','123456','男','1999-08-08','广东广州','lisi@163.com',2),
(NULL,'王二','123456','男','1999-08-08','广东广州','wanger@163.com',3);
注意:若字段省略,VALUES之后的值和顺序必须与表一一对应
更新
UPDATE `表名` SET `字段1`=值1,`字段2`=值2,`字段N`=值N WHERE 条件;
UPDATE `student` SET `stuName`='张三三',`stuEmail`='zhangsansan@163.com' WHERE `stuId`=1;
WHERE子句在SELECT详细说明,用于过滤数据,这里表示选择stuId为1的行,进行更新stuName和stuEmail字段。
删除
DELETE FROM `表名` WHERE 条件;
DELETE FROM `student` WHERE `stuId`=3;
TRUNCATE `表名`;
TRUNCATE `grade`;
TRUNCATE是删除表,再重新建立之前空行的表,理解为清理表。它和DELETE不同在于它会重置AUTO_INCREMENT计数。
一般业务中不会物理删除,会使用伪删除。
查询
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[into_option]
[FOR UPDATE | LOCK IN SHARE MODE]
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}
基本查询
SELECT `字段1`,`字段2`,`字段N` FROM `表名`;
SELECT VERSION(); -- 版本号
SELECT LAST_INSERT_ID(); -- 返回最后插入的AUTO_INCREMENT的值
SELECT UUID(); -- 生成随机的UUID值
SELECT @@AUTO_INCREMENT_INCREMENT; -- 自增步长
SELECT NOW(); -- 当前日期时间
SELECT CURRENT_DATE; -- 当前日期
SELECT CURRENT_TIME; -- 当前时间
去重数据
SELECT DISTINCT `字段1`,`字段2`,`字段N` FORM `表名`;
分页查询
SELECT `字段1`,`字段2`,`字段N` FORM `表名` LIMIT 行数;
SELECT `字段1`,`字段2`,`字段N` FORM `表名` LIMIT 起始偏移, 行数;
排序数据
SELECT `字段1`,`字段2`,`字段N` FROM `表名` ORDER BY `字段a` [DESC|ASC] [ ,`字段b` [DESC|ASC],`字段z` [DESC|ASc] ];
过滤数据
WHERE子句操作符
WHERE 字段 操作符 值
WHERE 条件a 逻辑操作符(AND或OR) 条件b
WHERE NOT 条件
WHERE 字段 IS NULL
WHERE 字段 IS NOT NULL
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| != | 不等于 |
| <> | 不等于 |
| < | 小于 |
| <= | 小等于 |
| > | 大于 |
| >= | 大等于 |
| BETWEEN a AND b | 指定a,b值之间 |
| IN (a,b,z) | 在指定括号内值的范围 |
| NOT | 逻辑否 |
| AND | 逻辑与 |
| OR | 逻辑或 |
注意:逻辑运算执行顺序 NOT > AND > OR。使用圆括号(),优先执行。
SELECT * FROM `student` WHERE `stuId`=1;
SELECT * FROM `student` WHERE `stuName`='张三';
SELECT * FROM `student` WHERE `stuId`!=1;
SELECT * FROM `student` WHERE `stuId`<>=1;
SELECT * FROM `student` WHERE `stuId`<3;
SELECT * FROM `student` WHERE `stuId`<=3;
SELECT * FROM `student` WHERE `stuId`>3;
SELECT * FROM `student` WHERE `stuId`>=3;
SELECT * FROM `student` WHERE `stuId` BETWEEN ;
模糊查询
SELECT `字段1`,`字段2`,`字段N` FROM `表名` WHERE `字段` LIKE '%值%';
计算字段
拼接字段
CONCAT(a,b)
起别名
`原字段名` AS `字段别名`
SELECT CONCAT(TRIM(`stuId`),TRIM(`stuName`)) AS `title` FROM `student`;
TRIM函数去掉串两边空格
表达式
SELECT 表达式;
SELECT 100*3-1 AS `result`;
常用函数
文本处理函数
| 函数 | 含义 |
|---|---|
| Left(str,len) | 返回串左边的字符 |
| Right(str,len) | 返回串右边的字符 |
| Length(str) | 返回串左边的字符 |
| Locate(substr,str) | 找出串中的子串 |
| Lower(str) | 将串转换为小写 |
| Upper(str) | 将串转换为大写 |
| Ltrim(str) | 去掉串左空格 |
| Rtrim(str) | 去掉串右空格 |
| Rtrim(str) | 去掉串左右空格 |
| Soundex(str) | 返回串的SOUNDEX值 |
| SubString(str FROM pos) | 返回子串的字符 |
| MD5(str) | 返回字符串MD5值 |
日期和时间处理函数
几个关键字:CURRENT_DATE、CURRENT_TIME分别表示当前的日期和时间
| 函数 | 含义 |
|---|---|
| AddDate(date, INTERVAL expr unit) | 增加一个日期(天、周等) |
| AddTime(time, expr) | 增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
| Date(expr) | 返回日期时间的日期部分 |
| Time(expr) | 返回日期时间的时间部分 |
| Now() | 返回当前日期和时间 |
| DateDiff(expr1,expr2) | 返回当前日期之差(expr1-expr2) |
| Date_Add(date,INTERVAL expr unit) | 高度灵活的日期运算函数(加减) |
| Date_Format(date,format) | 返回格式化的日期或时间串 |
| Day(date) | 返回一个日期的天数部分 |
| Month(date) | 返回一个日期的月数部分 |
| Year(date) | 返回一个日期的年数部分 |
| DayOfWeek(date) | 对于一个日期,返回对应的星期几(1周日 2周一 …) |
| Hour(time) | 返回时间的小时部分 |
| Minute(time) | 返回时间的分钟部分 |
| Second(time) | 返回时间的秒部分 |
数值处理函数
| 函数 | 含义 |
|---|---|
| Abs(x) | 返回一个数的绝对值 |
| Cos(x) | 返回一个弧度的余弦 |
| Exp(x) | 返回一个自然对数的指数值 |
| Mod(n,m) | 返回除操作的余数 |
| Pi() | 返回圆周率 |
| Rand() | 返回一个随机数 |
| Sin(x) | 返回一个弧度的正弦 |
| Sqrt(x) | 返回一个数的平方 |
| Tan(x) | 返回一个弧度的正切 |
聚合函数
聚集函数 运行在行组上,计算和返回单个值的函数
| 函数 | 含义 |
|---|---|
| AVG([DISTINCT] expr) | 返回某列的平均值 |
| COUNT(DISTINCT [expr][,expr]) | 返回某列符合表达式条件的行数 |
| MAX([DISTINCT] expr) | 返回某列的最大值 |
| MIN([DISTINCT] expr) | 返回某列的最小值 |
| SUM([DISTINCT]expr) | 返回某列值之和 |
重点看COUNT函数。
COUNT(*)对所有表进行计数,不管是列中包含的是空值还是非空值。但COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。所以COUNT(NULL)为0。
分组过滤
SELECT `字段1`,`字段2`,`字段N` FROM `表名` GROUP BY `列中字段` HAVING 条件;
SELECT `stuId`, `stuName`,`stuGender` FROM `student` GROUP BY `stuGender`,`stuId`, `stuName` HAVING `stuId` > 1;
注意:
1.GROUP BY 子句可以包含任意数目的列;
2.GROUP BY 子句不能使用聚合函数;
3.SELECT中出现的所有列和表达式,也在GROUP BY 中出现,但不使用别名;
4.若分组列中具有NULL值,则NULL将作为一个分组返回。若是多行NULL,它们将分成一组;
5.GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前;
6.在建立分组时,指定的所有列都一起计算,所以不能从个别的列取回数据。
7.如果检索列和聚合函数在SELECT中一起使用,GROUP BY 必须使用。
HAVING支持所有WHERE子句中的条件,它们句法相同,一个用于分组前的过滤行,一个分组后的过滤分组
子查询
子查询 SELECT语句中嵌套了其他的SELECT查询。子查询由内向外处理。
- 子查询过滤(常用且灵活)
- 子查询计算字段
子查询过滤
查询学生id为3的年级名称。
SELECT `gradeName`
FROM `grade`
WHERE `gradeId` IN (SELECT `gradeId`
FROM `student`
WHERE `stuId`=3);
WHERE 子句的列和SELECT 语句中列必须匹配,即具有相同数目的列。
子查询计算字段
查询各个年级的学生数量。
SELECT `gradeName`,
(SELECT COUNT(*)
FROM `student` WHERE `student`.`gradeId` = `grade`.`gradeId` ) AS count
FROM `grade`
ORDER BY `gradeName`;
级联查询
- 内部联结
- 外部联结
内部联结
基于两个表之间相等测试的联结。故又称等值联结。排除相同的列多次出现,则成为自然联结。特殊地,当两张表为同一张表,就成为自联结。
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
INNER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`;
SELECT `student`.*,`grade`.`gradeName`
FROM `student`,`grade`
WHERE `student`.`gradeId` = `grade`.`gradeId`;
外部联结
外部联结包含那些在相关表中没有关联行的行。
- 左外联结
- 右外联结
左外联结
包含了交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
LEFT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`;
不包含了交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
LEFT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`
WHERE `grade`.`gradeId` IS NULL;
右外联结
包含了交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
RIGHT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`;
不包含了交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
RIGHT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`
WHERE `student`.`gradeId` IS NULL;
注意:联结非常消耗性能,联结的表越多,性能下降越快,不要联结不必要的表
组合查询
多个SELECT结果合并
全联结包含交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
LEFT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`
UNION
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
RIGHT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`;
全联结不包含交集部分
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
LEFT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`
WHERE `grade`.`gradeId` IS NULL
UNION
SELECT `student`.*,`grade`.`gradeName`
FROM `student`
RIGHT OUTER JOIN `grade`
ON `student`.`gradeId` = `grade`.`gradeId`
WHERE `student`.`gradeId` IS NULL;
事务与SQL优化
见MySQL事务与SQL优化回顾。
索引
MySQL官方定义:帮助MySQL高效获取数据的数据结构,就是索引。
其底层的数据结构是B+树。
分类:
- 主键索引 (PRIMARY KEY)
- 唯一标识,主键列值不可重复,主键只能有一个,不可多个
- 唯一索引 (UNIQUE KEY)
- 避免重复的列值出现,唯一索引可以有多个
- 常规索引 (KEY|INDEX)
- 默认的
- 全文索引 (FULLTEXT INDEX)
- MYISAM 特有,用于快速定位和搜索
建表时增加索引
CREATE TABLE `表名` (
`属性1` 数据类型,
`属性2` 数据类型,
`属性3` 数据类型,
PRIMARY KEY(`属性1`)
UNIQUE KEY `属性2` (`属性2`),
KEY `属性3` (`属性3`)
) ENGINE=INNODB;
CREATE TABLE `表名` (
`属性1` 数据类型,
`属性2` 数据类型,
`属性3` 数据类型,
FULLTEXT(`属性1`)
) ENGINE=MYISAM;
建表后增加索引
ALTER TABLE `表名` ADD FULLTEXT INDEX `属性1` (`属性1`);
索引搜索
SELECT `属性` FROM `表名` WHERE MATCH(`属性1`) AGAINST('值');
索引其他命令
# 显示所有索引信息
SHOW INDEX FROM `表名`;
# 分析SQL语句执行状况 比如查询所需记录的行数
EXPLAIN SQL语句;
建议:
- 索引不是越多越好
- 不对变动大数据加索引
- 数据量小的表不加索引
- 索引一般加在常用查询的字段上
用户权限管理
新建一个用户
CREATE USER `用户名` IDENTIFIED BY '密码';
更改用户密码
ALTER USER `用户名` IDENTIFIED BY '密码';
重命名
RENAME USER `原名` TO `新名`
用户授权
GRANT 权限 ON `库名`.`表名` TO `用户`;
权限有SELECT、INSERT、UPDATE、DELETE等等,ALL PRIVILEGES 表示除了GRANT的所有权限。
权限撤销
REVOKE 权限 ON `库名`.`表名` FROM `用户`;
MySQL备份
保证重要数据不丢失,方便数据转移
# mysqldump -h 主机 -u 用户 -p 密码 库名 表名 > 文件名
mysqldump -h localhost -uroot -p123456 crashcourse student > data.sql
# mysqldump -h 主机 -u 用户 -p 密码 库名 表名1 表名2 表名N > 文件名
mysqldump -h localhost -uroot -p123456 crashcourse student teacher > data.sql
# mysqldump -h 主机 -u 用户 -p 密码 库名 > 文件名
mysqldump -h localhost -uroot -p123456 crashcourse > data.sql
导入
先登录数据库后
USE `crashcourse`;
SOURCE /path/to/data.sql
如何设计数据库
软件开发中数据库设计
- 分析需求:分析业务和需求处理的数据库的需求
- 概要设计:设计关系E-R图
设计数据库的步骤
- 收集信息,分析需求
- 要创建哪些表,表里有哪些需求
- 标识实体
- 把需求落实到字段
- 标识实体的关系
- 有一对一,多对多,一对多
数据库的三大范式
防止信息重复,减少数据冗余,防止异常。
- 第一范式(1NF)要求数据库的每一列都是不可在分割的原子数据项
- 第二范式(2NF)前提满足第一范式,确保数据库的每一列依赖于主键列(每张表只描述一件事)
- 第三范式(3NF)前提满足第一第二范式,确保数据库每列数据都和主键直接相关,不能间接相关
规范性和性能的问题
根据阿里规范,关联查询建议不超过3张表
- 考虑商业化的需求和目标,数据库性能更加重要
- 在考虑完性能问题后,适当考虑规范性的问题
- 有时需要故意增加一些冗余的字段(方便将多表查询变为单表查询)
- 有时故意增加一些计算字段(将大数据降低为小数据量的查询:索引)